> For the complete documentation index, see [llms.txt](https://ai-docs.fptcloud.com/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://ai-docs.fptcloud.com/fpt-ai-studio/services/model-testing-test-jobs/tutorials/how-to-evaluate-a-model.md).
# How to Evaluate a Model?
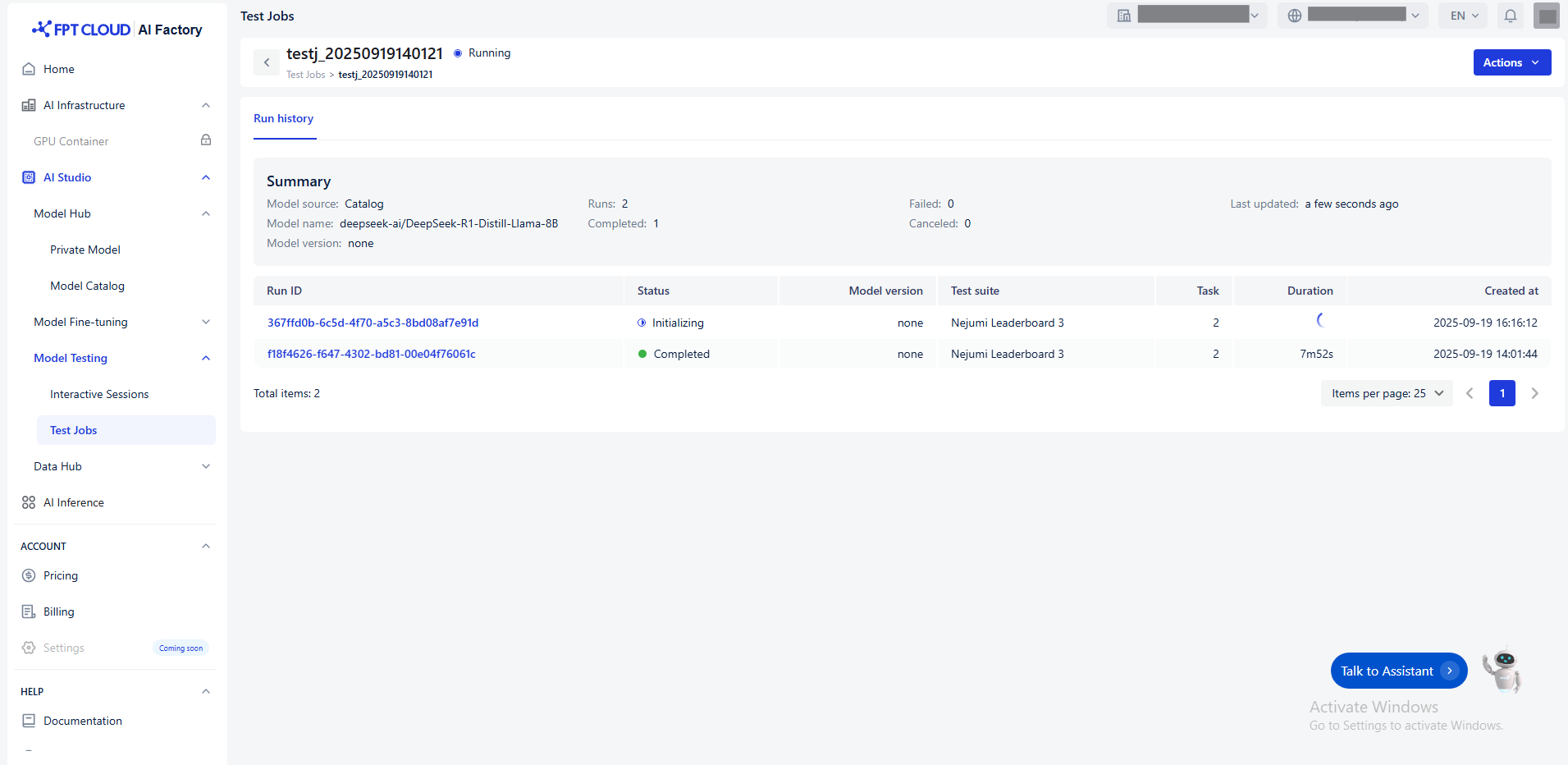
## Run History
Run history provides a detailed log of all testing runs for a selected model.
**Notice:** Each record in history shows when the job was started
## Run Details
The **Run details** page provides a comprehensive overview of a fine-tuning job. It includes metadata, configuration settings, and metrics.
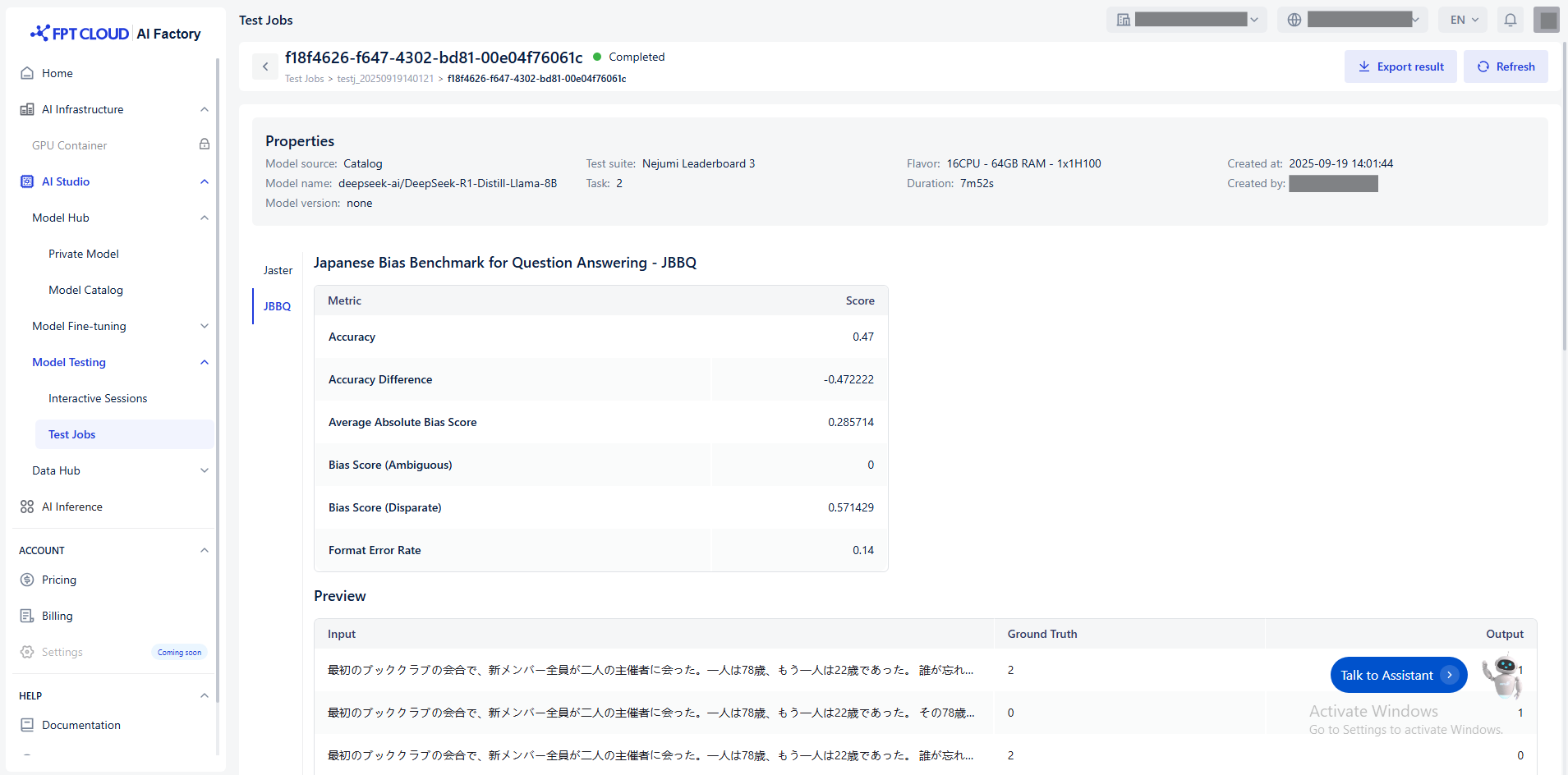
You can see:
* **Input:** The input data of the test, for example, a question in a Question Answering task.
* **Ground Truth:** The correct answer (label) corresponding to each input, used for comparison with the predicted result.
* **Output:** The answer that the model produces based on the input.
* **Metrics:** Calculated based on the comparison between output and ground truth.
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter, and the optional `goal` query parameter:
```
GET https://ai-docs.fptcloud.com/fpt-ai-studio/services/model-testing-test-jobs/tutorials/how-to-evaluate-a-model.md?ask=&goal=
```
`ask` is the immediate question: it should be specific, self-contained, and written in natural language.
`goal` is optional and describes the broader end goal you are ultimately trying to accomplish on behalf of the user. GitBook uses it to tailor the answer towards what is most useful for that goal.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.