
ログ分析チャットボットのための継続的事前学習
FPT AI Studioを使用したログ分析チャットボットの継続的事前学習チュートリアルです。詳細はGitHubリポジトリをご確認ください。
前提条件: このチュートリアルは「ログアナライザーチャットボット」を基盤としています。チャットボットのパイプライン、データセットの前処理、およびFPT AI Studioを使用した基本的な微調整フローを理解するため、まずそちらをお読みください。
1. 概要
継続的事前学習とは何か?
継続的事前学習(CPT)は、汎用的な事前学習とタスク特化型の微調整の中間的な適応ステップである。モデルを完全に一から訓練する代わりに、CPTは事前学習済みの大規模言語モデル(LLM)を、新たなドメイン特化データにさらすことで拡張する。これにより、モデルは汎用的な自然言語理解を維持しつつ、ドメイン固有の言語パターンを学習できる。
ログ分析においてCPTが特に重要な理由は、ログが自然言語と大きく異なる点にある:
構造化されたトークン(IPアドレス、タイムスタンプなど)を含む
文法や文脈が欠如していることが多い
トークン分布が自然言語コーパスから乖離している
生のログデータでベースLLMを直接微調整すると、極端なドメインシフトによる壊滅的忘却(catastrophic forgetting)を引き起こす可能性があります。CPTはこのギャップを埋めるため、まず解釈可能なドメイン関連自然言語データでモデルを適応させた後、実際のログタスクで微調整を行います。
動機
本研究は、論文「解釈可能なドメイン知識を用いたログ分析への大規模言語モデルの適応(Ji et al., CIKM 2025)」に触発されたものである。同論文では、ログのセマンティクスと自然言語による説明を融合した25万組以上のQ&Aペアを含むデータセット「NLPLog」を用いてCPT(継続的事前学習)により適応させたLLM「SuperLog」を紹介している。
我々は以下の同じ哲学を採用する:
CPTには解釈可能なQ&Aデータを使用する。
事前学習済みモデルを、より大規模なモデルから構築したデータで微調整する。
NLPメトリクスを用いて評価する。
継続的学習済み微調整モデルと、Log Analyzer Chatbotからの直接微調整モデルを比較する。
FPT AI Studio
FPT AI Studioを活用し、モデル開発ワークフロー全体を効率化・自動化します:
モデル微調整:Llama-3.1-8B-Instructモデルの継続的な事前学習と微調整を実施。
対話セッション:対話形式でモデルの挙動を実験し、微調整版をAPIとしてデプロイしてチャットボット統合を実現。
テストジョブ:複数のNLP指標を用いて指定テストセット上でモデル性能をベンチマークし、堅牢性と信頼性を確保します。
さらに、大規模モデルとデータセットの効率的な保存・管理のためにModel HubとData Hubを採用しています。 Model Hub Data Hub

2. 継続的事前学習
データ
継続的な事前学習には、「解釈可能なドメイン知識を用いた大規模言語モデルのログ分析への適応」(Ji et al., CIKM 2025)のNLPLogを利用する。以下はNLPLogのサンプルエントリである:
FPT AI Studioの事前学習用モデル微調整フォーマットに準拠し、SuperLog事前学習設定との一貫性を維持するため、データを人間とアシスタントの役割を持つテキスト形式に再フォーマットしました。再フォーマット後の例:
前処理後、トレーニングセットには合計1億1100万トークンが含まれていることが判明しました。
トレーニング済みデータセットのダウンロード手順:データをダウンロード
モデルとハイパーパラメータ
ベースモデル: meta-llama/Llama-3.1-8B-Instruct
ハイパーパラメータ:
インフラストラクチャ: H100 GPU 8基
トレーニング: モデルトレーニングプロセス中、モデルメトリクスセクションで損失値やその他の関連指標を監視できます。
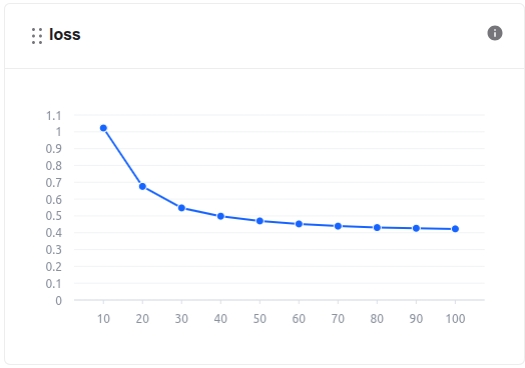
さらに、システム関連メトリクスは「システムメトリクス」セクションで確認できます。
トレーニング時間は50分52秒です。ファインチューンモデルの使用コストは約1.925ドルです。コストの説明:
FPT AI Studioでは、GPU時間あたり2.31ドルを課金します。重要な点として、実際のGPU使用時間のみ課金対象となり、モデルダウンロード、データダウンロード、データトークン化、Model Hubへのデータプッシュなどの作業時間は計算に含まれません。
簡略化のため、表示されている費用にはモデルダウンロード、データダウンロード、データトークン化、Model Hubへのデータプッシュに要した時間も含まれています。実際のところ、実際のGPU使用時間のみ課金されるため、実際の費用は表示値より低くなります。
3. 微調整
継続的事前学習ステップを完了した後、継続的に事前学習されたモデルの微調整を行います。使用する微調整データとハイパーパラメータは、ベースモデル meta-llama/Llama-3.1-8B-Instruct から直接微調整する場合と全く同じです(詳細は Log Analyzer Chatbot を参照)。
モデル: 継続的プリアートレーニング済み meta-llama/Llama-3.1-8B-Instruct
データ: 合成生成データセット: data/final_data/chat
トレーニングセット: 8,971 サンプル
検証セット: 500 サンプル
テストセット: 500 サンプル
トレーニングサブセット: 1,000 サンプル (デモ用)
ハイパーパラメータ:
インフラストラクチャ: 4台のH100 GPUでモデルをトレーニングし、分散データ並列処理(ddp)とFlashAttention 2およびLigerカーネルを活用してトレーニングプロセスを加速しました。グローバルバッチサイズは64に設定しました。
ログアナライザチャットボットと同様に、ベースモデルからの直接微調整と比較した結果として、テストジョブを用いた微調整後のモデルを評価します( Log Analyzer Chatbot):
Base Llama-3.1-8B-Instruct
0.27408
0.01905
0.08188
0.018422
0.062904
0.069208
Finetuned Llama-3.1-8B-Instruct
0.491492
0.28256
0.484142
0.173832
0.251358
0.449348
Finetuned Continual Pretrained Llama-3.1-8B-Instruct
0.494022
0.279686
0.486667
0.174316
0.253998
0.450784

注記:
🏆 ファインチューニング済みモデルの優れた性能: 「Finetuned Continual 8B」モデルと「Finetuned 8B」モデルは、すべての評価指標において「Base 8B」モデルを大幅に上回っています。これは、ベースモデルを特定のタスクに適応させる上でファインチューニングが極めて重要であることを示しています。
✨ 継続的事前学習のわずかな優位性: 「Finetuned Continual 8B」モデルは、ファジーマッチング、ROUGE-1、ROUGE-L、ROUGE-Lsumを含むほとんどの指標において、標準的な「Finetuned 8B」モデルに対し一貫してわずかな性能上の優位性を示しています。改善幅は小さいものの、継続的事前学習の付加価値を実証しています。
4. 結論
このチュートリアルでは、継続的事前学習と微調整を通じてLLaMA3.1-8B-Instructをログ分析に適応させる完全なワークフローを示しました。
主なポイント:
解釈可能なログQ&Aデータを用いた継続的事前学習は、モデルのドメイン理解を大幅に強化します。
その後の微調整により収束が加速し、解釈可能性が向上します。
ファジーマッチング、BLEU、ROUGEによる評価では、BLEUを除くほぼ全ての指標で一貫した改善が確認されました。
この手法はSuperLog(CIKM 2025)の最先端手法と一致し、解釈可能なドメイン知識の注入が生のログトレーニングよりも優れていることを裏付けています。
Last updated