
✌️ジョブの作成方法
モデルの選択
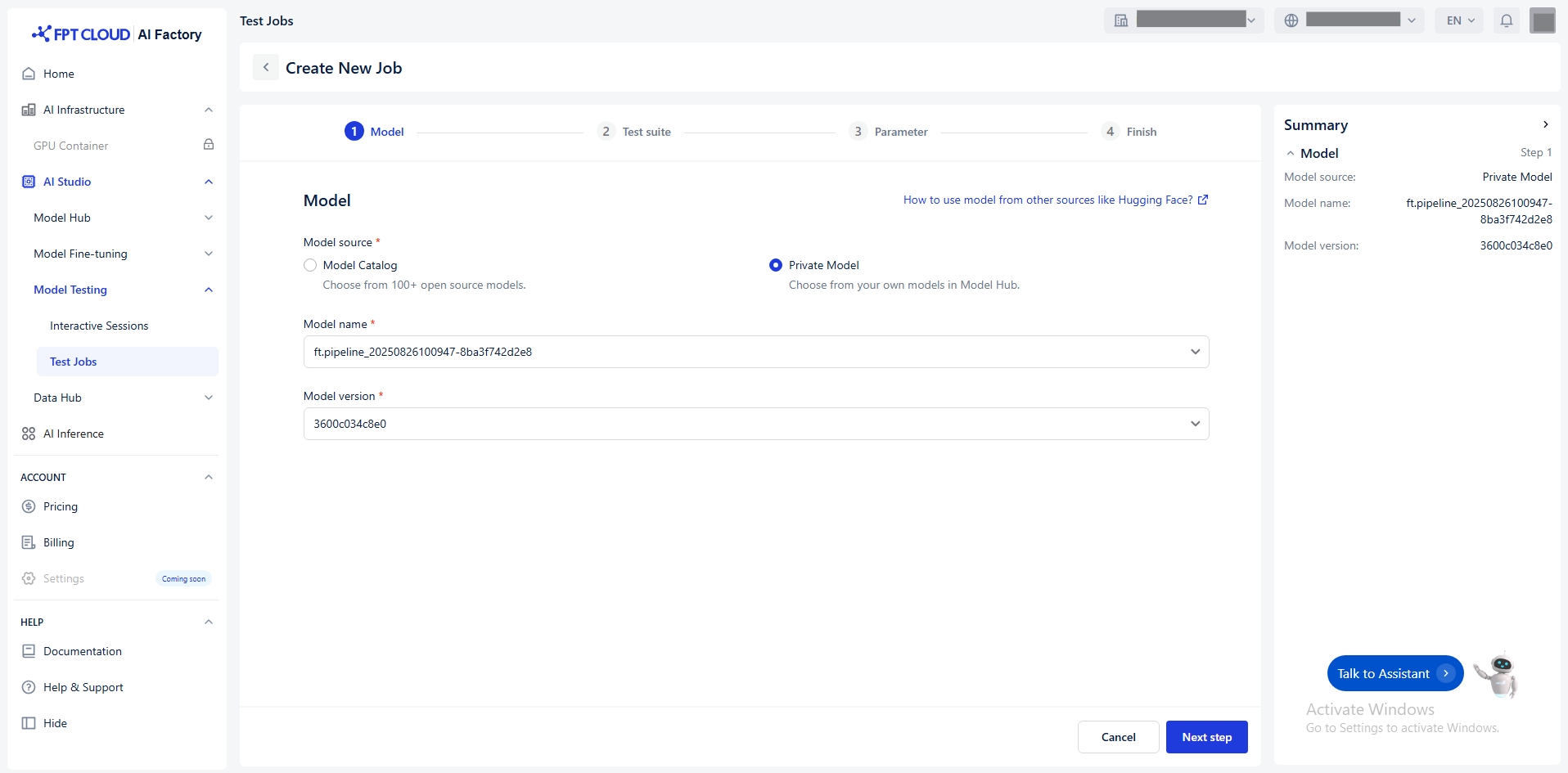
モデルハブからモデルを選択する方法は2通りあります:
モデルカタログ:DeepSeek、Gemma、Llama、Qwenなど、様々なプロバイダーからのモデルソ ースを保管するリポジトリ。
プライベートモデル:ユーザー所有モデルおよび微調整済みモデルのリポジトリ。これらのモ デルには必要なファイルがすべてアップロード済みである必要があります。互換性と準備完了を 示す特定のタグを含める必要があります。
例:
ft_Llama-3.1-8B_20250508124054_samples-15d5e2f6fe7
15d5e2f6fe7
Llama
LLM (→ 利用可能)
8B (→ 利用可能)
Instruction-tuned (→ 利用可能)
テストスイートの選択
モデルをテストする適切なテストスイートを選択してください。
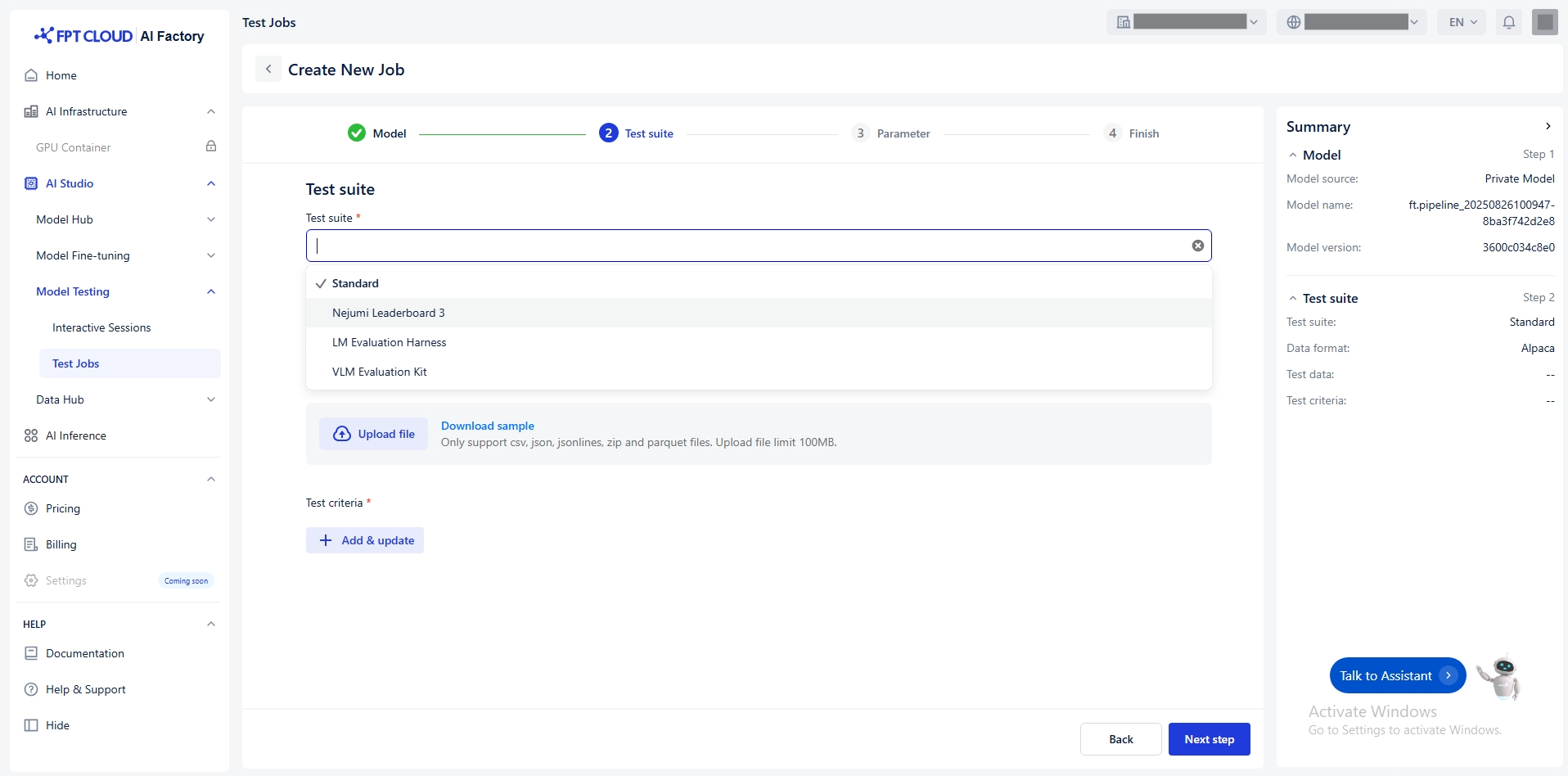
以下のテストスイートを提供します:
標準
独自のデータセットを使用したモ デル評価。
内部ベンチマーク、特定分野のタ スク(例:金融、医療...)
LM 評価ハーネス
多くの標準的なNLPベンチマーク で言語モデルを評価するための 汎用フレームワーク。参照: LM Evaluation Harness
英語中心のLLMを評価し、研究文 献との比較可能性を確保
データ形式の選択
テストスイート = 標準を選択する場合にのみデータ形式を選択してください
Alpaca
- CSV - JSON - JSONLINES - ZIP - PARQUET
制限100MB
ShareGPT
- JSON - JSONLINES - ZIP - PARQUET
制限 100MB
ShareGPT_Image
- ZIP - PARQUET
制限100MB
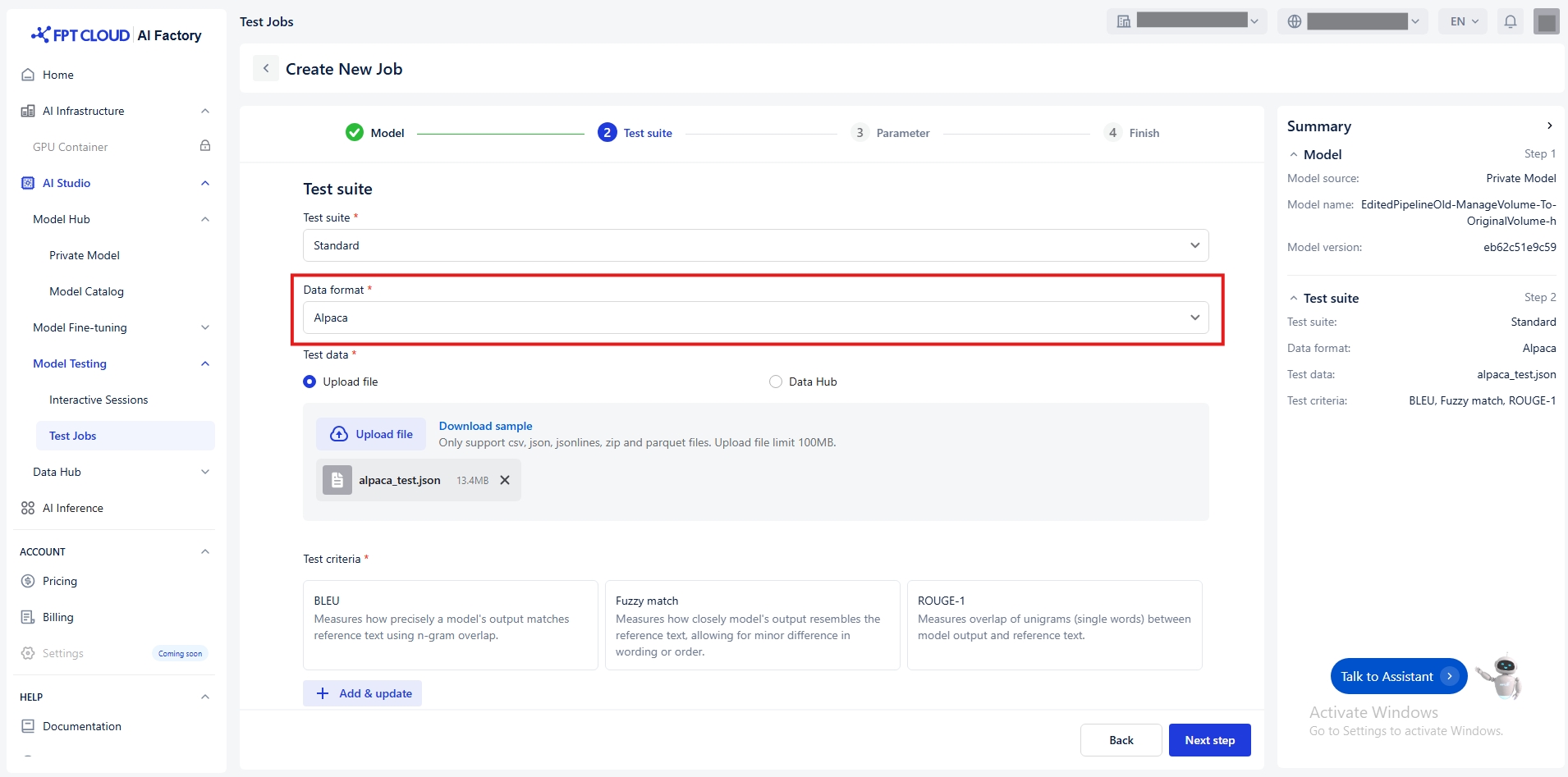
現在テスト用にサポートしているデータ形式は以下の通りです:
a/ Alpaca
Alpaca、教師あり微調整タスク向けに、入力と出力のペアを用いた指示順守形式でモデルを微調 整するために、非常にシンプルな構造を採用しています。基本構造は以下の通りです:
Instruction:モデルが実行すべき特定のタスクや要求を含む文字列。
Input: モデルがタスクを実行するために処理する必要がある情報を含む文字列。
Output: 指示と入力を処理して生成される、モデルが返すべき結果を表す文字列。
詳細な構造:
例:
サンプル: https://github.com/fpt-corp/ai-studio-samples/tree/main/sample-datasets/alpaca
サポートされているファイル形式: .csv, .json, .jsonlines, .zip, .parquet
b/ ShareGPT
ShareGPTは、ユーザーとAIアシスタント間の複数ターンにわたる会話(やり取りのあるチャット )を表現するために設計されています。これは、複数ターンにわたる文脈のある会話を処理する必 要がある対話システムやチャットボットのモデルをトレーニングまたは微調整する際に一般的に使 用されます。
Each data sample consists of a conversations array, where each turn in the chat includes:
from: 発言者 — 通常
"human"または"system".value: その話者からの実際のメッセージテキスト。
詳細な構造:
例:
サンプル: https://github.com/fpt-corp/ai-studio-samples/tree/main/sample-datasets/sharegpt
サポートされているファイル形式: .json, .jsonlines, .zip, .parquet
c/ ShareGPT_Image
ShareGPT_Image は、ShareGPT マルチターンチャット形式の拡張機能です。 マルチモーダル学習、すなわち会話においてテキストと画像の両方を扱うモデルの学習に特化して設 計されています。
これは、画像と自然言語を同時に処理する必要がある視覚言語モデル(VLMs)の微調整に使用されます 。
構造は以下の通りです:
下の会話ターン一覧
"message"(ShareGPTと同様).A field called
"image"or"image_path"that points to the image used in the conversation (using format png, jpg, jpeg)
注意:
画像を表示させる必要があるチャットコンテンツには、必ず
imageトークンを含める必要があります。複数の画像がある場合:
画像パスは
images配列内で定義する必要があります。チャットフロー内の画像の位置は、
imageトークンで示されますチャット内の
imageトークンの数は、images配列内のアイテム数と一致する必要があります。画像は出現順にマッピングされ、各
imageトークンはimages配列の対応する画像に置き換えられます。
詳細な構造:
例:
サンプル: https://github.com/fpt-corp/ai-studio-samples/tree/main/sample-datasets/sharegpt-image
サポートされているファイル形式:.zip, .parquet
Select Test Data
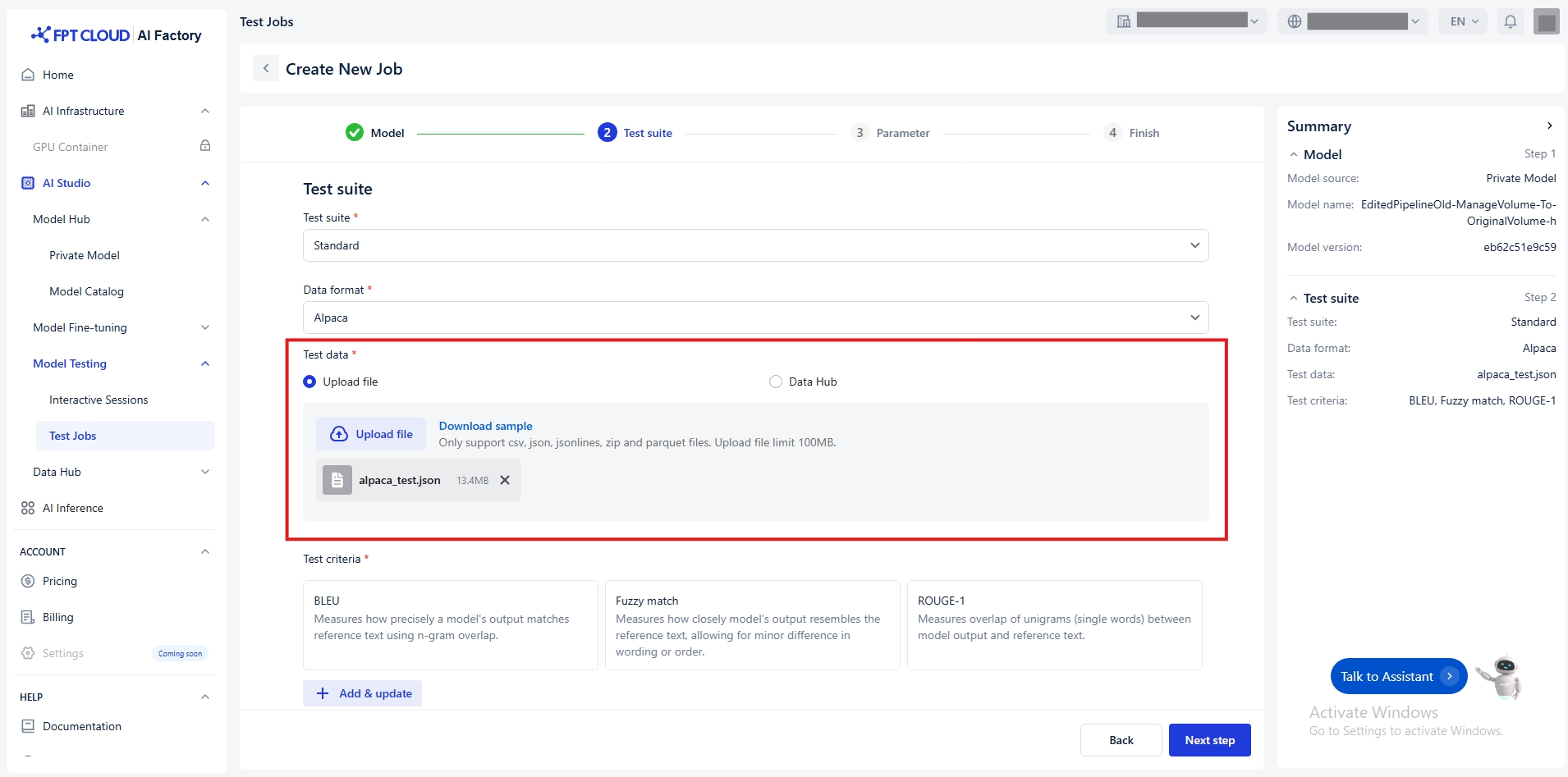
You have two ways to transfer the Test data:
Connect to Data Hub
Click Data Hub
Select a connection or dataset from the Data Hub. Notice: Ensure the dataset is compatible with the selected format.
(Optional) Click Open Data Hub to preview or manage datasets.
(Optional) Click Reload icon to update connection and dataset list.
Follow the detailed guide Data Hub
Alpaca
- CSV - JSON - JSONLINES - ZIP - PARQUET
Limit 100MB
ShareGPT
- JSON - JSONLINES - ZIP - PARQUET
Limit 100MB
ShareGPT_Image
- ZIP - PARQUET
Limit 100MB
Notice: Ensure the file matches the selected data format
Upload a file
Default value Upload file
Choose a local file from your computer.
(Optional) Click Download sample to see an example of the expected format.
Test Criteria

Click Add & update button
The Tasks window appears. Select the task type:
Text similarity: Measures similarity metrics between model outputs and reference texts.
Click Next to open the list of available metrics
Select one or more metrics
Click Update to apply changes
The following metrics of Text similarity are available:
BLEU
Measures how precisely a model’s output matches reference text using n-gram overlap.
Evaluating translation and short text similarity.
Fuzzy Match
Measures how closely the model’s output resembles the reference text, allowing for minor differences in wording or order.
Checking approximate correctness.
ROUGE-1
Measures unigram (single word) overlap between model output and reference text.
Short summarization and text generation tasks.
ROUGE-2
Measures bigram (two-word sequence) overlap between model output and reference text.
Evaluating contextual accuracy.
ROUGE-L
Measures the longest common subsequence (LCS) between model output and reference text to capture fluency and word order similarity.
Longer text evaluation where structure matters.
ROUGE-LSUM
Measures LCS-based similarity across multiple sentences, suitable for evaluating longer summaries.
Summarization tasks.
タスク
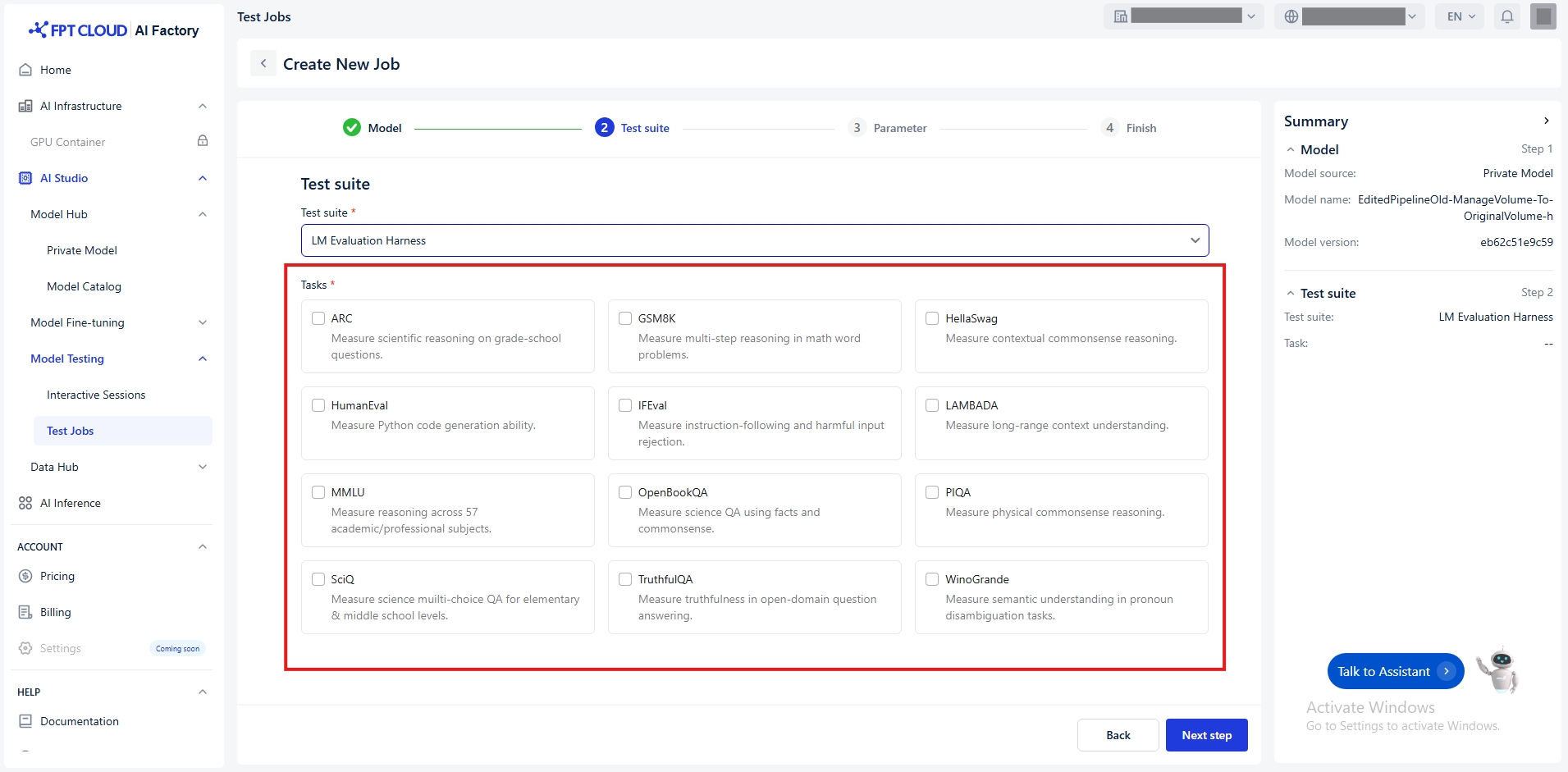
選択したテストスイートに応じて、以下のタスクを提供します:
Nejumi Leaderboard 3
Jaster
モデルの日本語理解・処理能力を測定する。
JBBQ
日本語の質問応答におけるLLMの社会的バイアスを測定する。
JtruthfulQA
日本語の質問に対する模範解答の真実性を測定する。
LM評価ハーネス
ARC
小学校レベルの質問で科学的推論を測定する。
GSM8K
数学の文章題における多段階推論を測定する。
HellaSwag
文脈に応じた常識的推論を測定する。
HumanEval
Pythonコード生成能力を測定する。
IFEval
指示に従う能力と有害な入力の拒否を測定する。
LAMBADA
長距離の文脈理解を測定する。
MMLU
57の学術・専門分野における推論能力を測定する。
OpenBookQA
科学的な品質保証を事実と常識を用いて測定する。
PIQA
物理的な常識的推論を測定する。
SciQ
小学校・中学校レベル向け理科の多肢選択式問題の質を測定する。
TruthfulQA
オープンドメイン質問応答における真実性の測定
Winogrande
代名詞の曖昧性解消タスクにおける意味理解を測定する。
VLM評価キット
ChartQA
図表に基づくデータ解釈および質問応答能力を測定する。
DocVQA
文書画像における質問応答性能を測定する。
InfoVQA
画像に埋め込まれた情報に基づいて質問応答を測定する。
MTVQA
多言語の視覚的テキスト質問応答性能を測定する。
OCRBench
様々なデータセットにおける光学式文字認識の精度を測定する。
パラメータの設定
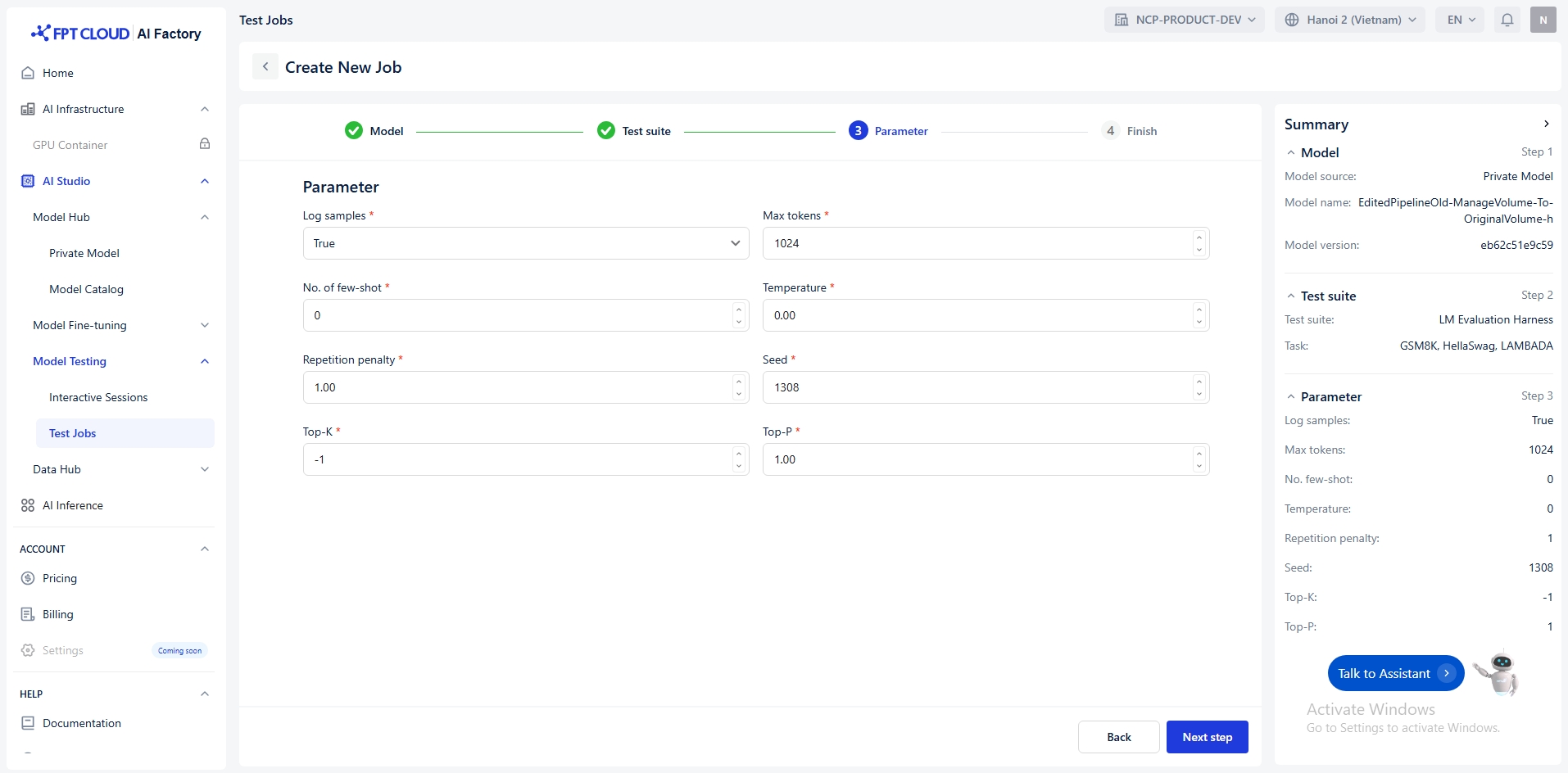
パラメータを使用すると、テスト中のモデルの動作を調整できます。以下に各パラメータとその目的を説明します:
ログサンプル
モデルの出力とモデル に入力されたテキスト が保存されます
bool
真 / 偽
最大トークン数
生成するトークンの最大数
整数
(0, +∞)
少数のショット数
コンテキストに配置す る少数のショット例の 数。整数で指定する必 要があります。
整数
[0, +∞)
温度
サンプリングの温度
浮動小数点数
[0, +∞)
繰り返しペナルティ
プロンプトと生成され たテキストに現れるか どうかに基づいて新し いトークンにペナルティ を課す浮動小数点数。
値が 1 より大きい場合 新しいトークンを 奨励する。
値 < 1繰り返 しを奨励する 。
浮動小数点数
(0, 5)
シード
再現性のための乱数 シード
整数
[0, +∞)
上位K
考慮する上位トークンの 累積確率を制御する整数 。すべてのトークンを考 慮するには-1を設定しま す。
整数
-1 or (0, +∞)
上位P
考慮対象となる上位トー クンの累積確率を制御 する浮動小数点数。すべ てのトークンを考慮する には1に設定します。
浮動小数点数
(0, 1]
完了
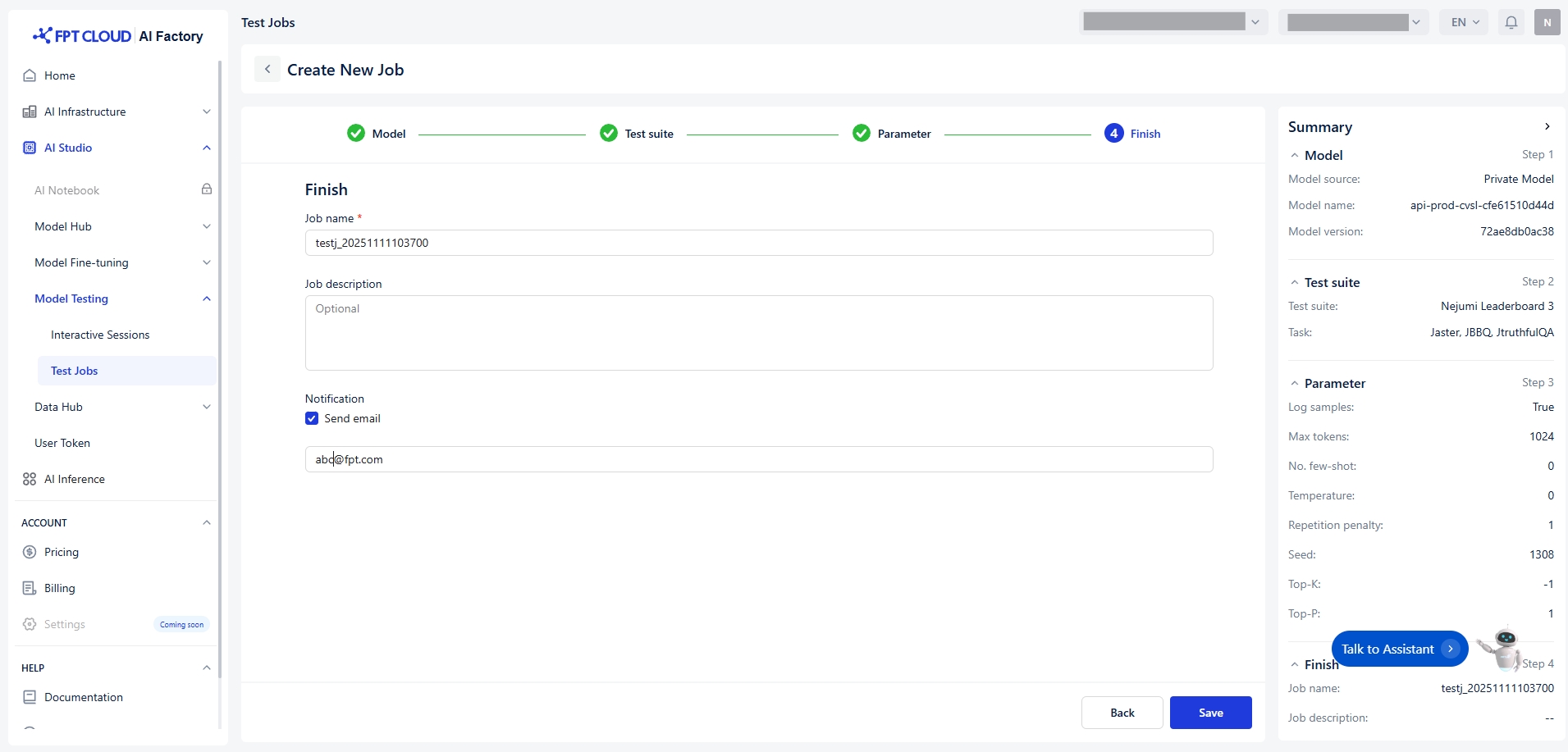
最後に、以下の条件を満たす一意のジョブ名(例: testj_20250919145022)を入力する必要があります:
文字または数字で始まる
アルファベット(a-z, A-Z)、数字(0-9)、アンダースコア「_」、ハイフン「-」のみ使用
最大100文字
重複しない名前
最大200文字のオプションのメモ付きジョブ記述を行い、パイプラインが成功または失敗した際にメール通 知([email protected])を受け取ります。
Last updated