
データセットの選択
まず第一に、最適なデータセットを準備する必要があります。これは、意図したユースケースにおけるモデル の性能に直接影響するためです。
良質なデータセットが実現すること:
残存する課題に対処するための事例を収集する。
モデルが特定の側面でまだ十分でない場合、それらの側面を正しく行う方法をモデルに直接示 すトレーニング例を追加してください。
既存の例を精査して問題点を洗い出してください。
モデルに文法、論理、またはスタイルの問題がある場合、データに同様の問題がないか確認してくだ さい。例えば、モデルが「この会議をあなたのためにスケジュールします」と誤って発言する場合、 既存の例がモデルに「実際にはできない新しいことをできる」と誤って学習させていないか確認して ください
データのバランスと多様性を考慮してください。
データ内のアシスタント応答の60%が「この質問には答えられません」と返答している場合、推論時 にその応答が5%に抑えられるよう設定すると、拒否応答が過剰に発生する可能性が高い。
トレーニング例には応答に必要な情報が全て含まれていることを確認してください。
モデルの学習例に、会話の前文に存在しない特性に対するアシスタントの賛辞が含まれている場合 、モデルは個人の特性に基づいてユーザーを称賛するよう学習させたい場合、情報を虚構する(幻覚 を生成する)可能性があります。
トレーニング例における合意と一貫性を確認してください。
複数の人がトレーニングデータを作成した場合、モデルの性能は人同士の一致度と整合性のレベルに よって制限される可能性が高いです。例えば、テキスト抽出タスクにおいて、抽出されたスニペット について人々が70%しか合意していなければ、モデルはこれ以上の性能を発揮できないでしょう。
推論時に期待される通り、全てのトレーニング例が同一形式であることを確認してください
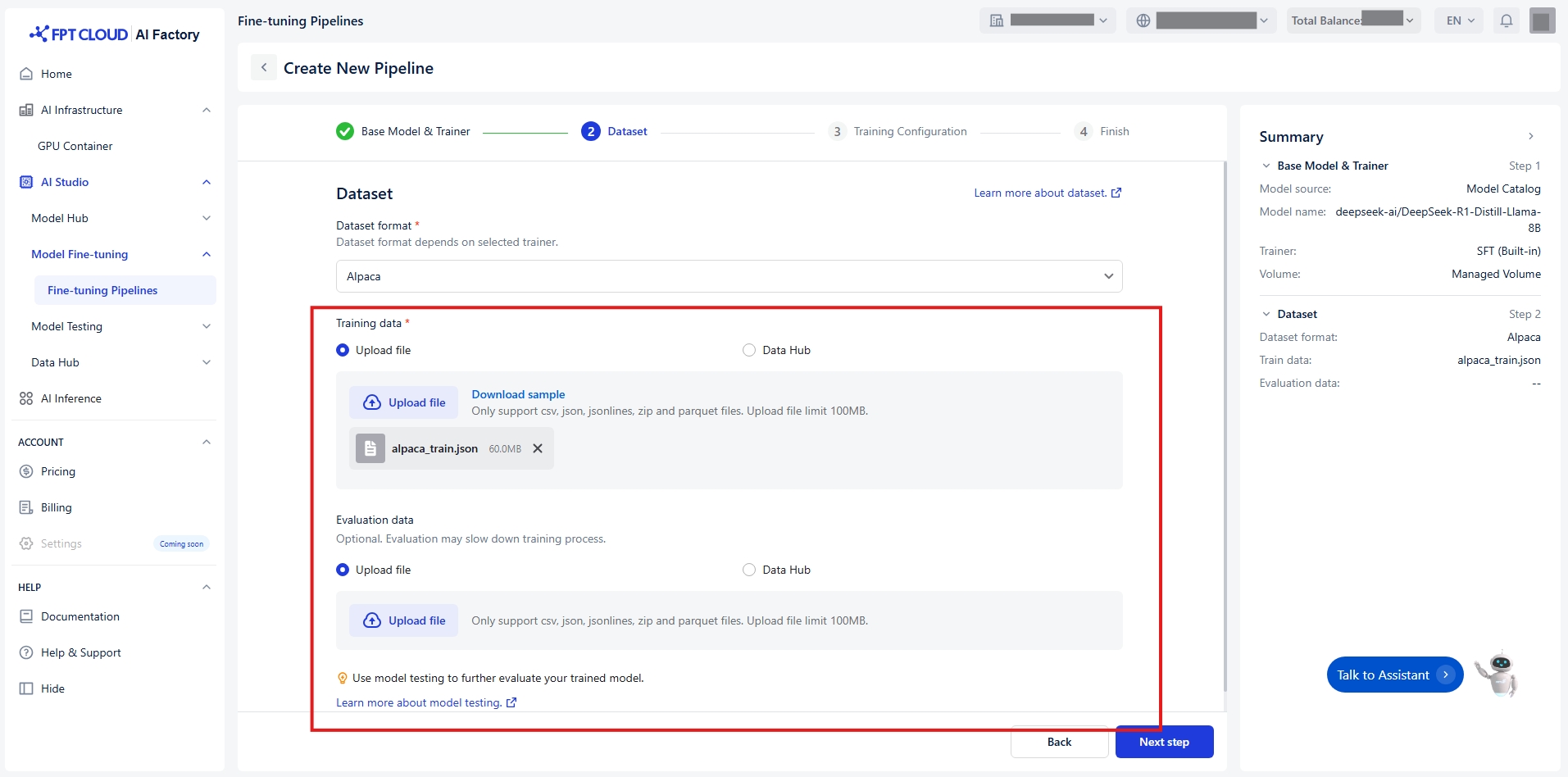
トレーニングデータと評価データを転送するには、次の2つの方法があります:
ファイルをアップロードする
デフォルト値 ファイルをアップロード
お使いのコンピュータからローカルファイルを選択してください。
(任意)期待されるフォーマットの例を確認するには「サンプルをダウンロード」をクリックしてくださ い。
注意: ファイルが選択したデータ形式と一致していることを確認してください
SFT
Alpaca
CSV JSON JSONLINES ZIP PARQUET
制限100MB
SFT
ShareGPT
JSON JSONLINES ZIP PARQUET
制限100MB
SFT
ShareGPT_Image
ZIP PARQUET
制限100MB
DPO
ShareGPT
JSON JSONLINES ZIP PARQUET
制限100MB
事前トレーニング
Corpus
TXT JSON JSONLINES ZIP PARQUET
制限100MB
データハブに接続
データハブをクリック
データハブから接続またはデータセットを選択してください。注意:データセットが選択した形 式と互換性があることを確認してください。
(オプション) データハブを開くをクリックして、データセットをプレビューまたは管理します。
(オプション) リロードアイコンをクリックして接続とデータセットリストを更新します。
詳細なガイド「データハブ」に従ってください
Last updated