
ハイパーパラメータの設定
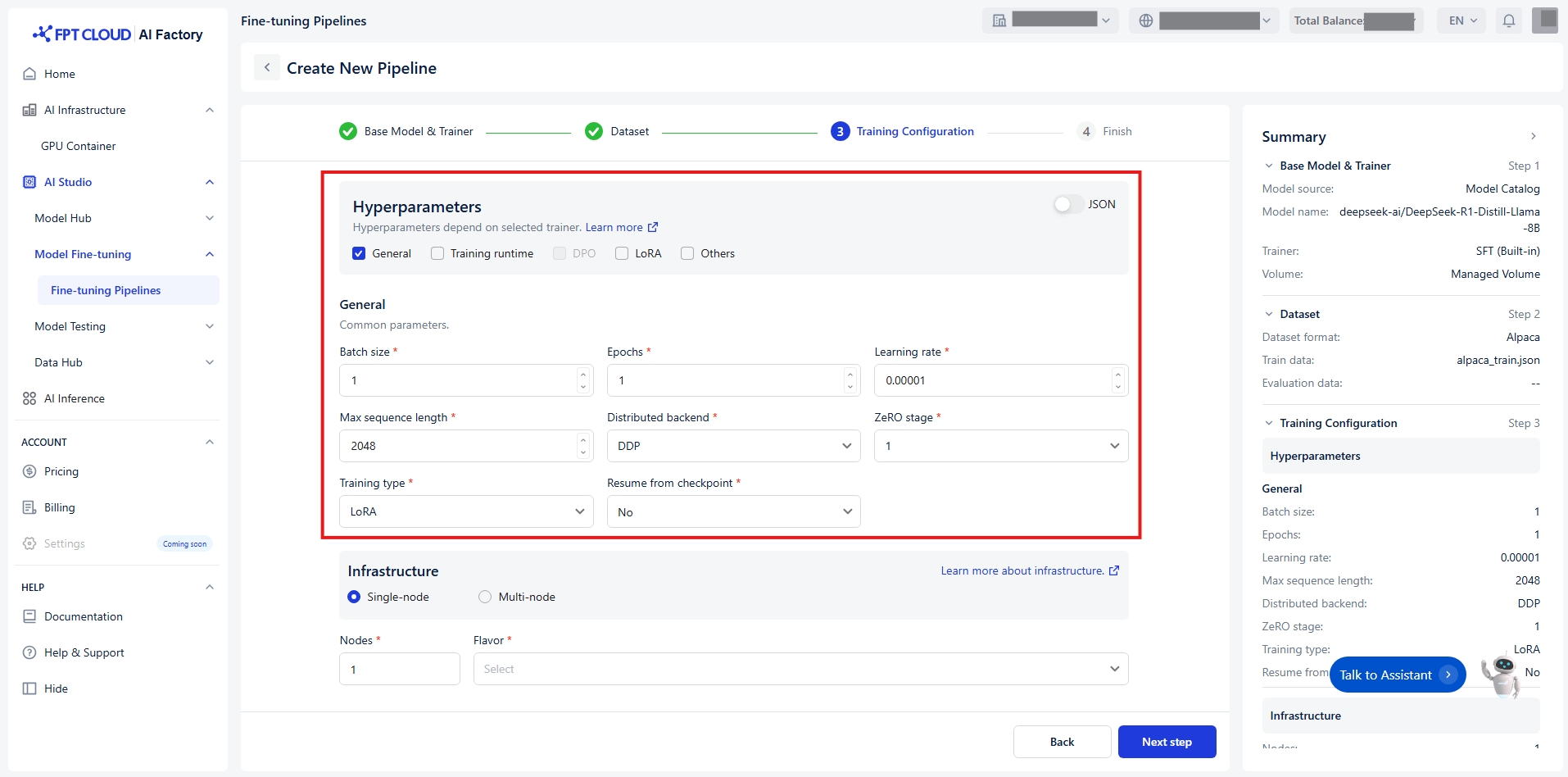
ハイパーパラメータは、トレーニングプロセス中にモデルの重みがどのように更新されるかを制御します。 設定を容易にするため、ハイパーパラメータを機能と関連性に基づいて5つの明確なグループに分類します :
グループ1 - 全般
トレーニングプロセスのコア設定。
バッチサイズ
モデルが重みを更新する 前に、1回の順伝播と逆 伝播で処理する例の数 。大きなバッチはトレ ーニングを遅くします が、より安定した結果 を生む可能性がありま す。 分散トレーニングの 場 合、これは各デバイス上 のバッチサイズです。
整数
[1, +∞)
エポック
エポックとは、モデルト レーニング中に全トレ ーニングデータを一度 完全に処理する単位で す。通常は複数のエポ ックを実行し、モデル が反復的に重みを最適 化できるようにします 。
整数
[1, +∞)
学習率
モデルの学習済みパラ メータに対する変更の 大きさを調整します。
浮動小数点
(0, 1)
最大シーケンス長
最大入力長。これより 長いシーケンスはこの 値で切り詰められます。
整数
[1, +∞)
分散バックエンド
分散トレーニングに使 用するバックエンド。
列挙型[文字列]
DDP, DeepSpeed
ZeROステージ
DeepSpeed ZeROアル ゴリズムを適用するス テージ。分散バックエン ドの場合にのみ適用 = DeepSpeed の場合の み適用。
列挙型[整数]
1, 2, 3
トレーニングタイプ
使用するパラメータ モード。
列挙型[文字列]
フル、LoRA
チェックポイントからの再 開
トレーニングエンジン が再開するチェックポ イントの相対パス。
Union[bool, string]
いいえ, 最後のチェック ポイント, チェックポイ ントへのパス
グループ 2 - トレーニング実行環境
トレーニングの効率とパフォーマンスを最適化します。
勾配蓄積ステップ数
後方伝播/更新パスを実 行する前に勾配を蓄積 するための更新ステップ 数。
整数
[1, +∞)
混合精度
使用する混合精度の種類。
列挙型[文字列]
Bf16, Fp16, None
量子化ビット
オンザフライ量子化でモ デルを量子化するビット 数。 現在、トレーニングタ イプ = LoRA の場合にの み適用可能。
列挙型[文字列]
なし
オプティマイザー
トレーニングに使用するオ プティマイザー。
列挙型[文字列]
Adamw, Sgd
重みの減衰
オプティマイザーに適 用する重み減衰。
浮動小数点
[0, +∞)
最大勾配ノルム
勾配クリッピングの最大ノ ルム。
浮動小数点
[0, +∞)
勾配チェックポイント機能 を無効化
勾配チェックポイントの無 効化を行うかどうか。
Bool
True, False
フラッシュアテンション v2
フラッシュアテンショ ンバージョン2を使用す るかどうか。
Bool
True, False
LRウォームアップ手順
学習率0から学習率までの線形ウォームアップに使用されるステップ数。
整数
[0, +∞)
LRウォームアップ比率
線形ウォームアップに使用される総トレーニングステップ数の比率。
フロート
[0, 1)
LR スケジューラ
使用する学習率スケジュー ラ。
列挙型[文字列]
Linear, Cosine, Constant
完全決定論
分散トレーニングで再現 可能な結果を確保します 。重要: これはパフォー マンスに悪影響を与える ため、デバッグ時のみ使 用してください。 Trueの場合、Seedの設定は 効果を持ちません。
Bool
True, False
Seed
再現性のための乱数 シード。
整数
[0, +∞)
グループ3 - DPO
トレーナー = DPO を使用する場合にこのグループを有効にしてください。
DPOラベル平滑化
DPO の堅牢な DPO ラ ベル平滑化パラメータ は 0 から 0.5 の間でな ければなりません。
浮動小数点
[0, 0.5]
優先度ベータ
優先度損失におけるベ ータパラメータ。
浮動小数点
[0, 1]
選好微調整混合率
DPOトレーニングにおける SFT損失係数。
浮動小数点
[0, 10]
選好損失
使用するDPO損失の種類 。
列挙型[文字列]
シグモイド、ヒンジ、Ipo 、Ktoペア、Orpo、 Simpo
SimPO gamma
SimPO損失における目 標報酬マージン。該当す る場合にのみ使用され る。
浮動小数点
(0, +∞)
グループ4 - LoRA
トレーニングタイプ = LoRA を使用する場合にこのグループを有効にします。
マージアダプター
LoRAアダプターをベー スモデルにマージして最 終モデルを提供するかど うか。マージしない場合 、トレーニング終了後は LoRAアダプターのみが 保存される。
Bool
True, False
LoRAアルファ
LoRA のアルファパラメー タ。
整数
[1, +∞)
LoRAのドロップアウト
LoRA のドロップア ウト率。
浮動小数点
[0, 1]
LoRAランク
LoRA行列のランク。
整数
[1, +∞)
ターゲットモジュール
量子化または微調整の対象 となるモジュール。
文字列
全線形
グループ 5 - その他
微調整の進捗状況の追跡および保存方法を制御します。
チェックポイント戦略
トレーニング中に 採用するチェック ポイント保存戦略 。 「best」のみ 評価戦略が「no」でな い場合にのみ適用可能 。
列挙型[文字列]
いいえ、エポック、ステッ プ数
チェックポイントステップ数
チェックポイント戦略が 有効な場合、2回のチェ ックポイント保存まで のトレーニングステッ プ数 = stepの場合に2回のチェ ックポイント保存が行わ れるまでのトレーニング ステップ数。
整数
[1, +∞)
評価戦略
トレーニング中に採 用する評価戦略。
列挙型[文字列]
いいえ、エポック、ステッ プ
評価ステップ
評価戦略がステップの 場合、2回の評価間の 更新ステップ数 = steps の場合。 設定されていない場合 、デフォルトでは「ロ ギングステップ数」と 同じ値になります。
整数
[1, +∞)
チェックポイント数
値が渡された場合、チェ ックポイントの総数を 制限します。
整数
[1, +∞)
ベストチェックポイ ントの保存
最良のチェックポイン トをトラッキングして 保持するかどうか。現 在はFalseのみをサポート。
Bool
False
ロギングステップ
標準出力ログやMLflowデー タポイントを含む、イベン ト間のステップ数。 logging_steps = -1は全ステ ップでログを記録すること を意味します。
整数
[0, +∞)
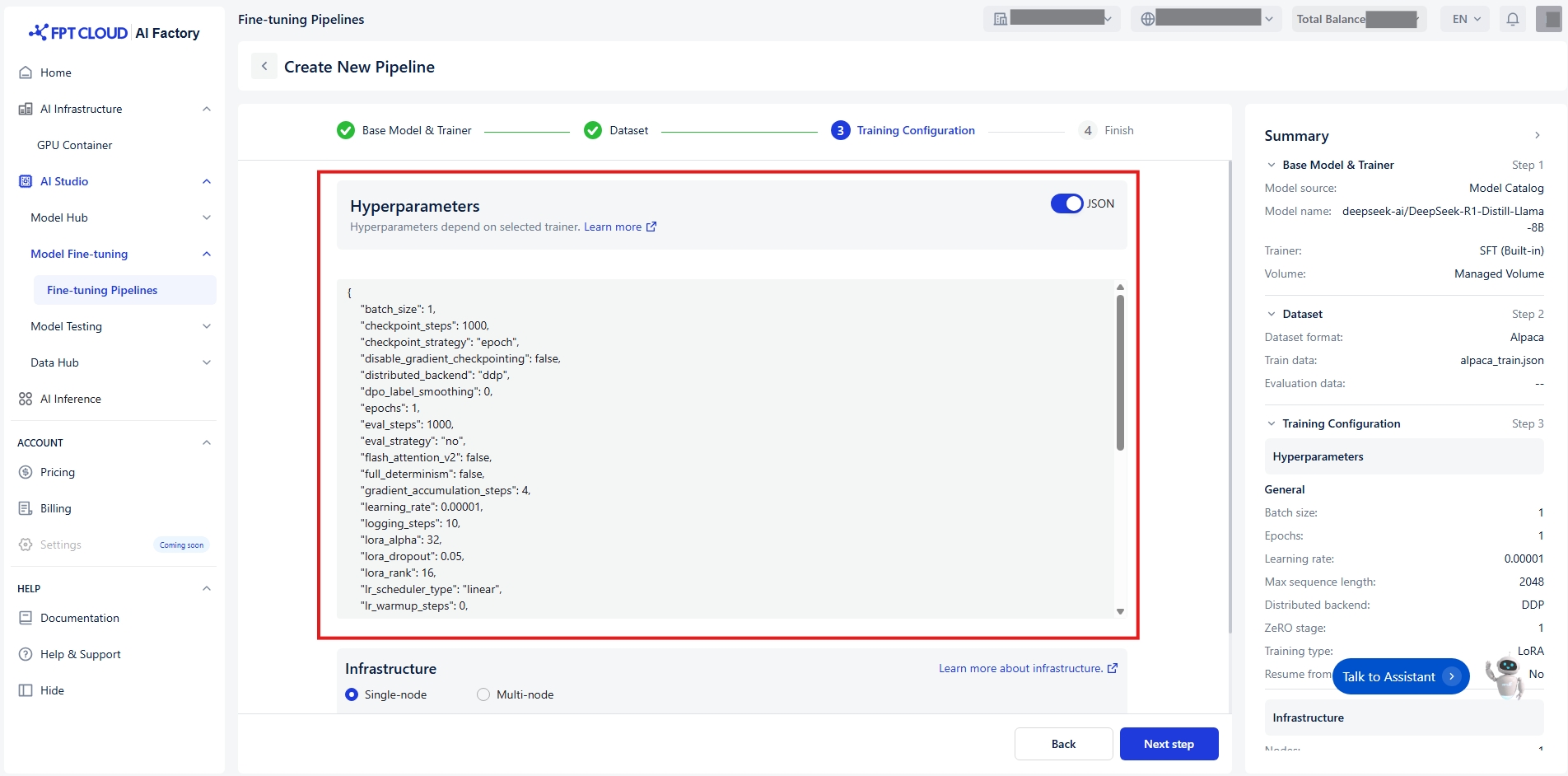
または、トグルJSONを切り替えることでハイパーパラメータを素早く設定できます:
Last updated