
🔬Continual Pretraining for Log Analysis Chatbot
Here is a tutorial for Continual Pretraining for Log Analysis Chatbot using FPT AI Studio. Check the GitHub repository for more details.
Prerequisite: This tutorial builds upon Log Analyzer Chatbot. Make sure you’ve read it first to understand our chatbot’s pipeline, dataset preprocessing, and basic fine-tuning flow with FPT AI Studio.
1. Overview
What is Continual Pretraining?
Continual Pretraining (CPT) is an intermediate adaptation step between general pretraining and task-specific fine-tuning. Instead of training a model entirely from scratch, CPT extends a pretrained large language model (LLM) by exposing it to new, domain-specific data. This allows the model to learn domain language patterns while preserving its general natural language understanding.
For log analysis, CPT is especially crucial because logs differ significantly from natural language:
They contain structured tokens (IP addresses, timestamps,...).
They often lack grammar and context.
Their token distribution diverges from natural text corpora.
Directly fine-tuning a base LLM on raw logs may lead to catastrophic forgetting due to extreme domain shifts. CPT bridges this gap by first adapting the model on interpretable, domain-related natural language data before fine-tuning on real log tasks.
Motivation
This work is inspired by the paper Adapting Large Language Models to Log Analysis with Interpretable Domain Knowledge (Ji et al., CIKM 2025). The paper introduces SuperLog, an LLM adapted through CPT using a dataset called NLPLog, which contains over 250K Q&A pairs blending log semantics with natural language explanations.
We adopt the same philosophy:
Use interpretable Q&A data for CPT.
Fine-tune the pretrained model with data built from the larger model.
Evaluate using NLP Metrics.
Compare continual-pretrained fine-tuned model with directly fine-tuned model from Log Analyzer Chatbot.
FPT AI Studio
We utilize FPT AI Studio to streamline and automate the entire model development workflow:
Model Fine-tuning: continual pretrain and fine-tune the Llama-3.1-8B-Instruct model.
Interactive Session: experiment with the model’s behavior in dialogue form and deploy the fine-tuned version as an API for chatbot integration.
Test Jobs: benchmark model performance on a designated test set using multiple NLP metrics to ensure robustness and reliability.
In addition, Model Hub and Data Hub are employed for efficient storage and management of large models and datasets.

2. Continual Pretraining
Data
For continual pretraining, we utilize NLPLog from “Adapting Large Language Models to Log Analysis with Interpretable Domain Knowledge” (Ji et al., CIKM 2025). Below is a sample entry from NLPLog:
To align with FPT AI Studio’s Model fine-tuning format for pretraining and to maintain consistency with the SuperLog pretraining setup, we reformatted the data into a text format with Human and Assistant roles. An example after reformatting:
After preprocessing, we found that the training set includes a total of 111 million tokens. Instructions for downloading ready-training dataset: load data
Refer: reformat_code
Model & Hyperparameters
Base Model: meta-llama/Llama-3.1-8B-Instruct
Hyperparameters:
Infrastructure: 8 H100 GPUs
Training: During the model training process, we can monitor the loss values and other related metrics in the Model metrics section.
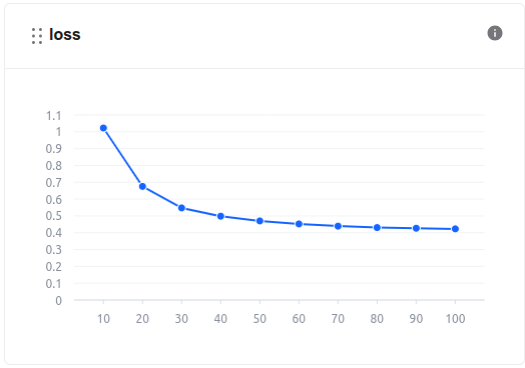
train loss In addition, we can observe the system-related metrics in the System metrics section.
Training time is 50m52s. The cost of using the fine-tune model is ~$1.925. Explanation of Costs:
At FPT AI Studio, we charge $2.31 per GPU-hour. Importantly, we only charge for actual GPU usage time and time spent on tasks such as model downloading, data downloading, data tokenization, and pushing data to the Model Hub is not included in the calculation.
Please note that, for simplicity, the costs shown include the time spent on model downloading, data downloading, data tokenization, and pushing data to the model hub. In practice, since we only charge for actual GPU usage time, the real cost will be lower than the value shown.
3. Fine-tuning
After completing the continual pretraining step, we perform fine-tune of the continual pretrained model. The fine-tune data and hyper-parameters we use are exactly the same as fine-tuning directly from the base model meta-llama/Llama-3.1-8B-Instruct (see more details at: Log Analyzer Chatbot)
Model: Continual Pretrained meta-llama/Llama-3.1-8B-Instruct
Data: The synthetically generated dataset: data/final_data/chat
Train set: 8,971 samples
Val set: 500 samples
Test set: 500 samples
Train subset: 1,000 samples (for demo purpose)
Hyper-parameters:
Infrastructure: We trained the model on 4 H100 GPUs, leveraging distributed data parallelism (ddp) along with FlashAttention 2 and Liger kernels to accelerate the training process. The global batch size was set to 64.
Similar to Log Analyzer Chatbot, we evaluate the model after fine-tuning with Test Jobs, the results compared with fine-tuning directly from the base model:

Note:
🏆 Superior Performance of Finetuned Models: Both the "Finetuned Continual 8B" and "Finetuned 8B" models dramatically outperform the "Base 8B" model across all evaluation metrics. This highlights the critical importance of finetuning for adapting a base model to a specific task.
✨ Slight Edge for Continual Pre-training: The "Finetuned Continual 8B" model consistently shows a slight performance advantage over the standard "Finetuned 8B" model in most metrics, including Fuzzy Match, ROUGE-1, ROUGE-L, and ROUGE-Lsum. While the improvements are marginal, they demonstrate the added value of continual pre-training.
4. Conclusion
In this tutorial, we demonstrated a full workflow for adapting LLaMA3.1-8B-Instruct to log analysis through continual pretraining and fine-tuning.
Key takeaways:
Continual pretraining on interpretable log Q&A data significantly enhances model domain understanding.
Fine-tuning afterward leads to faster convergence and higher interpretability.
Evaluation with Fuzzy Matching, BLEU, and ROUGE shows consistent improvement across almost all metrics, except for BLEU.
This approach aligns with state-of-the-art methods from SuperLog (CIKM 2025), confirming that interpretable domain knowledge injection is superior to raw log training.
Last updated
Was this helpful?