
🔬Log Analyzer Chatbot
Here is a tutorial on building a Log Analyzer Chatbot using FPT AI Studio. Check the GitHub repository for more details.
Overview
Log Analyzer Chatbot demonstrates how a Large Language Model (LLM) can serve as an intelligent assistant for log analysis, helping users find root causes, summarize logs, detect patterns, and interactively explore system behaviors through natural conversation.
Powered by a fine-tuned Llama-3.1-8B-Instruct model, the chatbot interprets raw log data, identifies underlying issues, summarizes key insights, and delivers clear, human-readable explanations via an intuitive chat interface.
We utilize FPT AI Studio to streamline and automate the entire model development workflow:
Model Fine-tuning: train and adapt the Llama-3.1-8B-Instruct model for domain-specific log analysis.
Interactive Session: experiment with the model’s behavior in dialogue form, compare performance before and after fine-tuning, and deploy the fine-tuned version as an API for chatbot integration.
Test Jobs: benchmark model performance on a designated test set using multiple NLP metrics to ensure robustness and reliability.
In addition, Model Hub and Data Hub are employed for efficient storage and management of large models and datasets.
Pipeline

The end-to-end pipeline for this project includes the following stages:
Data Preparation
Download and preprocess log data from a public repository (loghub2.0).
Chunk raw log files into manageable samples.
Model Training
Fine-tune meta-llama/Llama-3.1-8B-Instruct on the synthesized dataset.
Use Data Hub and Model Hub for dataset and model management.
1. Data Preparation
For this project, we utilized a publicly available log dataset.
Data Source: The log data was obtained from the Loghub repository. Loghub is a collection of system log datasets from various real-world systems, making it an excellent resource for developing and testing log analytics tools.
Data Chunking: The raw log files was chunked into smaller samples, each containing between 50 and 150 lines. This was done to create manageable contexts for the data synthesis model and to simulate the batch processing nature of the final application.
Refer: chunking code
2. Synthetic Data Generation with gpt-4o-mini
To train our smaller model effectively, we needed a labeled dataset that identified potential risks and summarized log entries. Instead of manually labeling the data, which is time-consuming and requires domain expertise, we leveraged a larger, more powerful model to generate synthetic training data.
Teacher Model:
gpt-4o-miniwas used for this task due to its strong reasoning and instruction-following capabilities in math and coding.Process: Each log data chunk was processed by
gpt-4o-miniusing task-specific prompts tailored for different log analysis objectives:Output Format: The prompt strictly enforced a JSON output format, which was then used to create our structured training dataset.
3. Model Training on FPT AI Studio
With our synthetic dataset ready, the next step was to fine-tune a smaller, more efficient model that could serve as an intelligent assistant. We fine-tuned the model using the LoRA technique.
Model: meta-llama/Llama-3.1-8B-Instruct.
Data: The synthetically generated dataset: data/final_data/chat
Train set: 8,971 samples
Val set: 500 samples
Test set: 500 samples
Train subset: 1,000 samples (for demo purpose)
By fixing the hyperparameters and varying only the number of training samples and GPUs, we obtained the following results:
Base Model
Train Samples
Val Samples
Test Samples
GPUs
Training Time
Our Cost ($2.31/GPU-hour)
Llama-3.1-8B-Instruct
8,971
500
500
4
2h19m55s
$5.39
Llama-3.1-8B-Instruct
8,971
500
500
8
1h15m29s
$2.89
Llama-3.1-8B-Instruct
1,000
500
500
4
21m22s
$0.85
Explanation of Costs:
At FPT AI Studio, we charge $2.31 per GPU-hour. The table above shows the estimated cost of running this tutorial. Importantly, we only charge for actual GPU usage time and time spent on tasks such as model downloading, data downloading, data tokenization, and pushing data to the Model Hub is not included in the calculation.
Please note that, for simplicity, the costs shown include the time spent on model downloading, data downloading, data tokenization, and pushing data to the model hub. In practice, since we only charge for actual GPU usage time, the real cost will be lower than the values shown in the table.
The data is uploaded to Data Hub for management. For datasets larger than 100 MB, we first upload the data to S3, then create a Connection in Data Hub, and finally create a Dataset in Dataset Management that points to the corresponding S3 dataset path. To upload data to S3, please refer to the code in: upload_s3.py
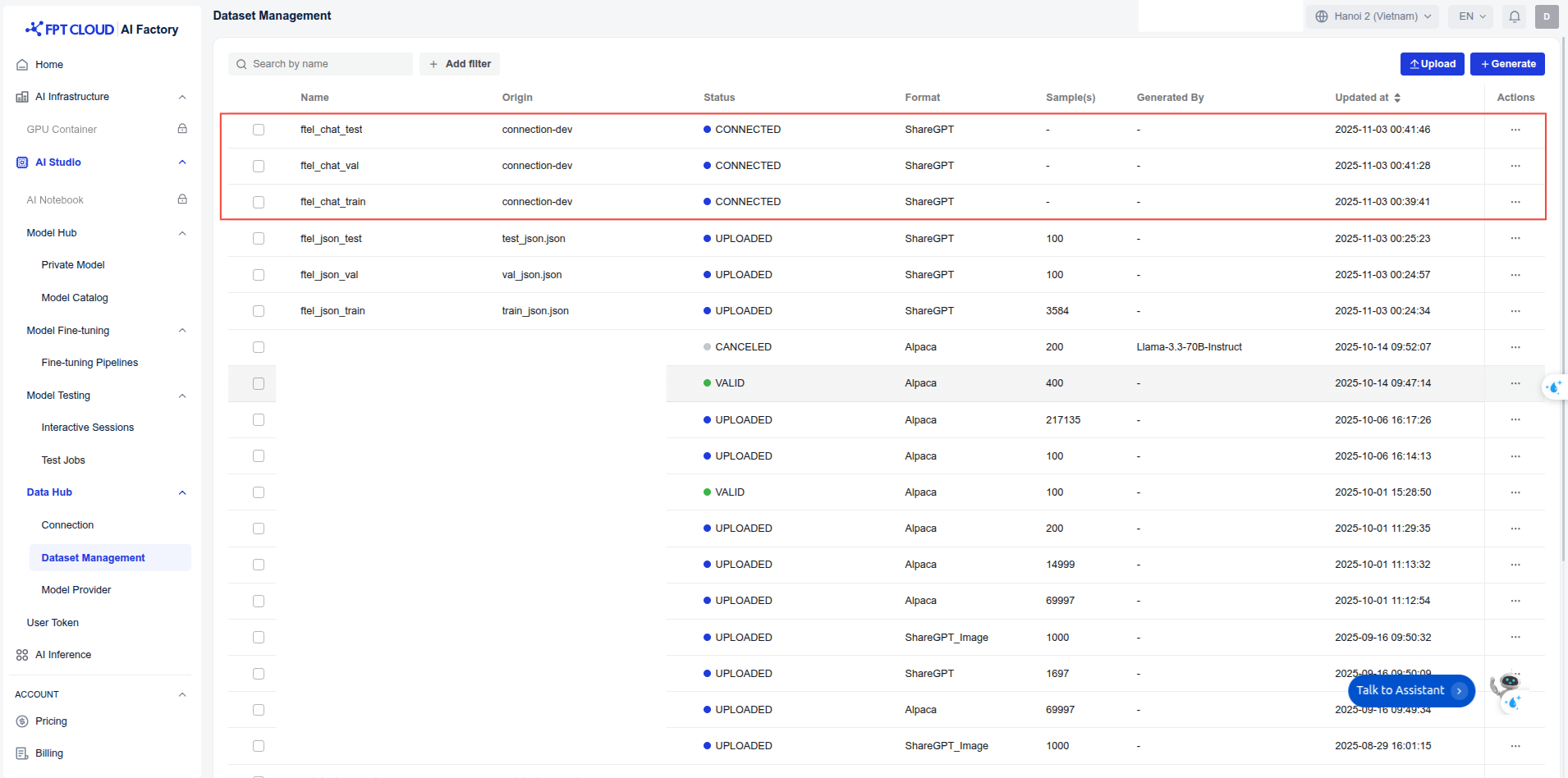
For log-related tasks, the context length is typically very long. The ideal context length to train our model should be 16k tokens, but for demo purpose, we set max_sequence_length = 8192 for faster training.
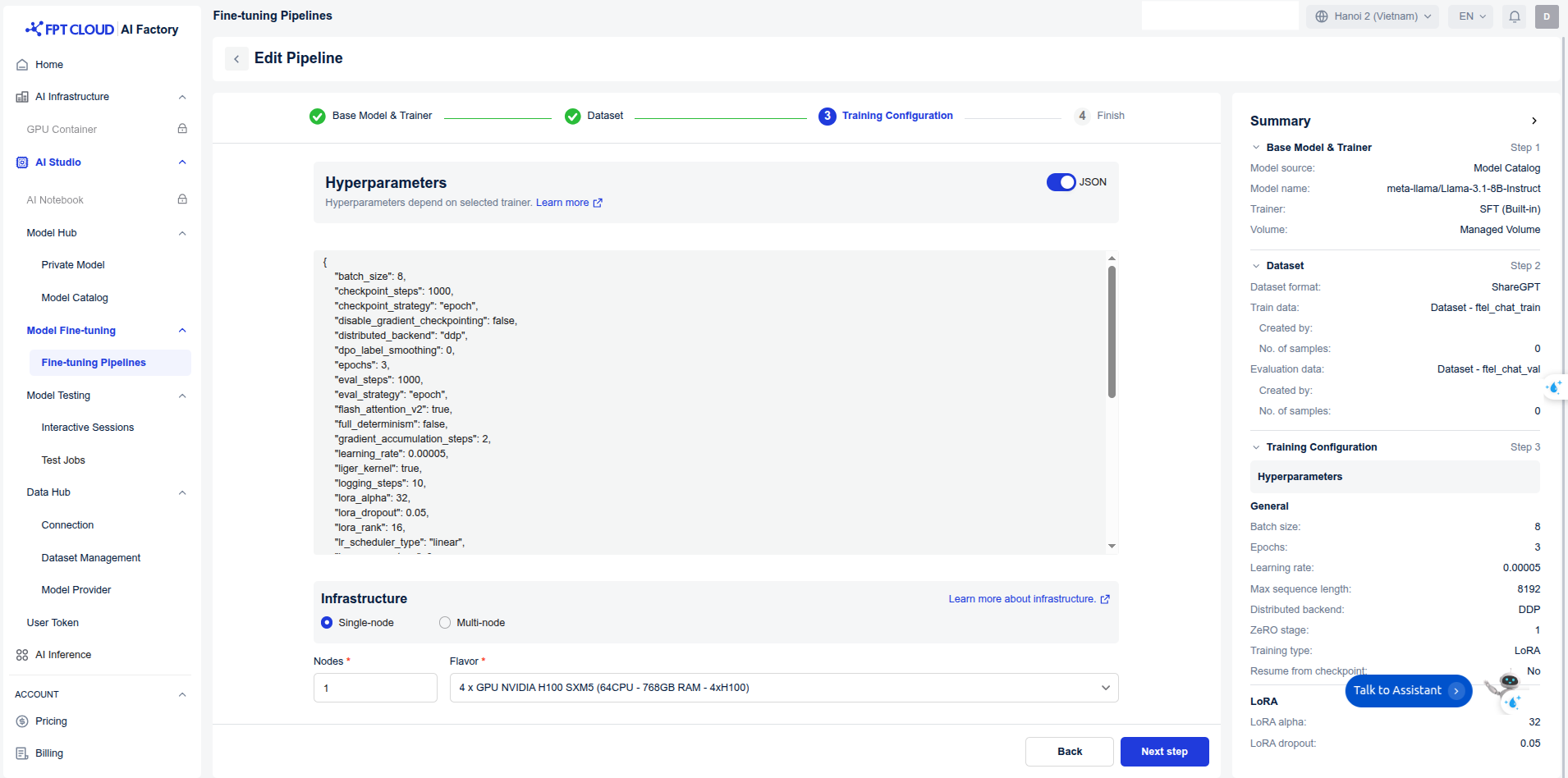
Hyper-parameters:
Infrastructure: We trained the model on 4 H100 GPUs, leveraging distributed data parallelism (ddp) along with FlashAttention 2 and Liger kernels to accelerate the training process. The global batch size was set to 64.
Training: Create pipeline and start training.
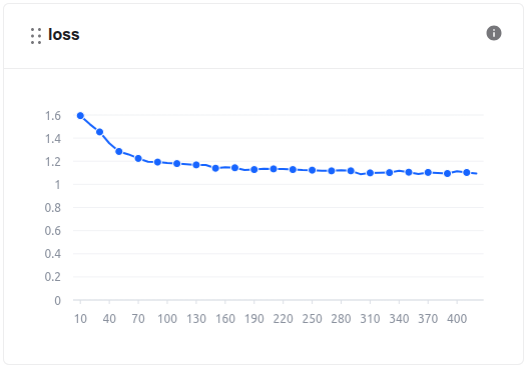
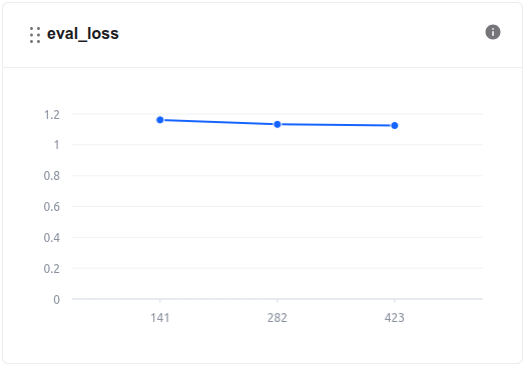
During the model training process, we can monitor the loss values and other related metrics in the Model metrics section.
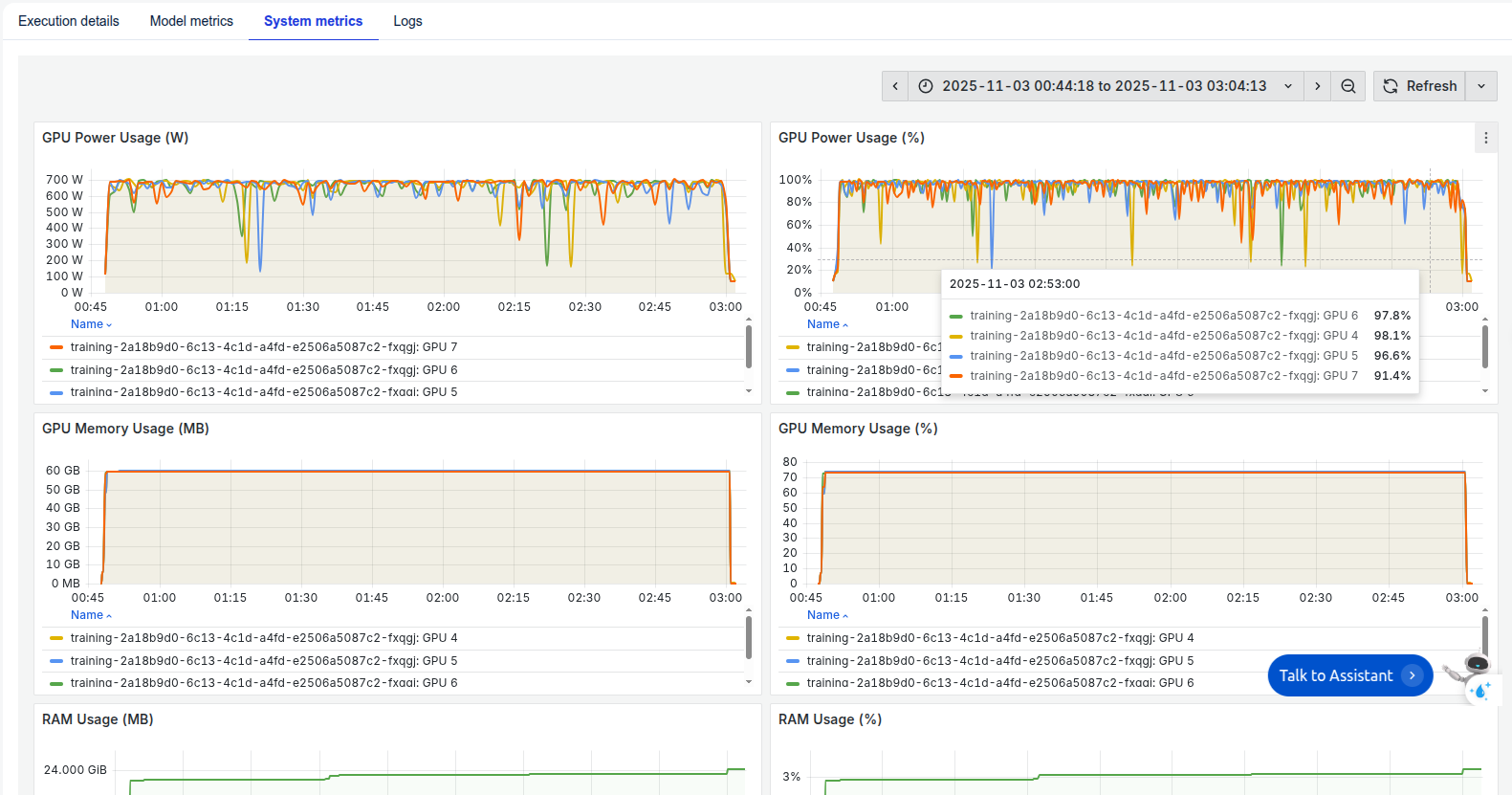
In addition, we can observe the system-related metrics in the System metrics section.
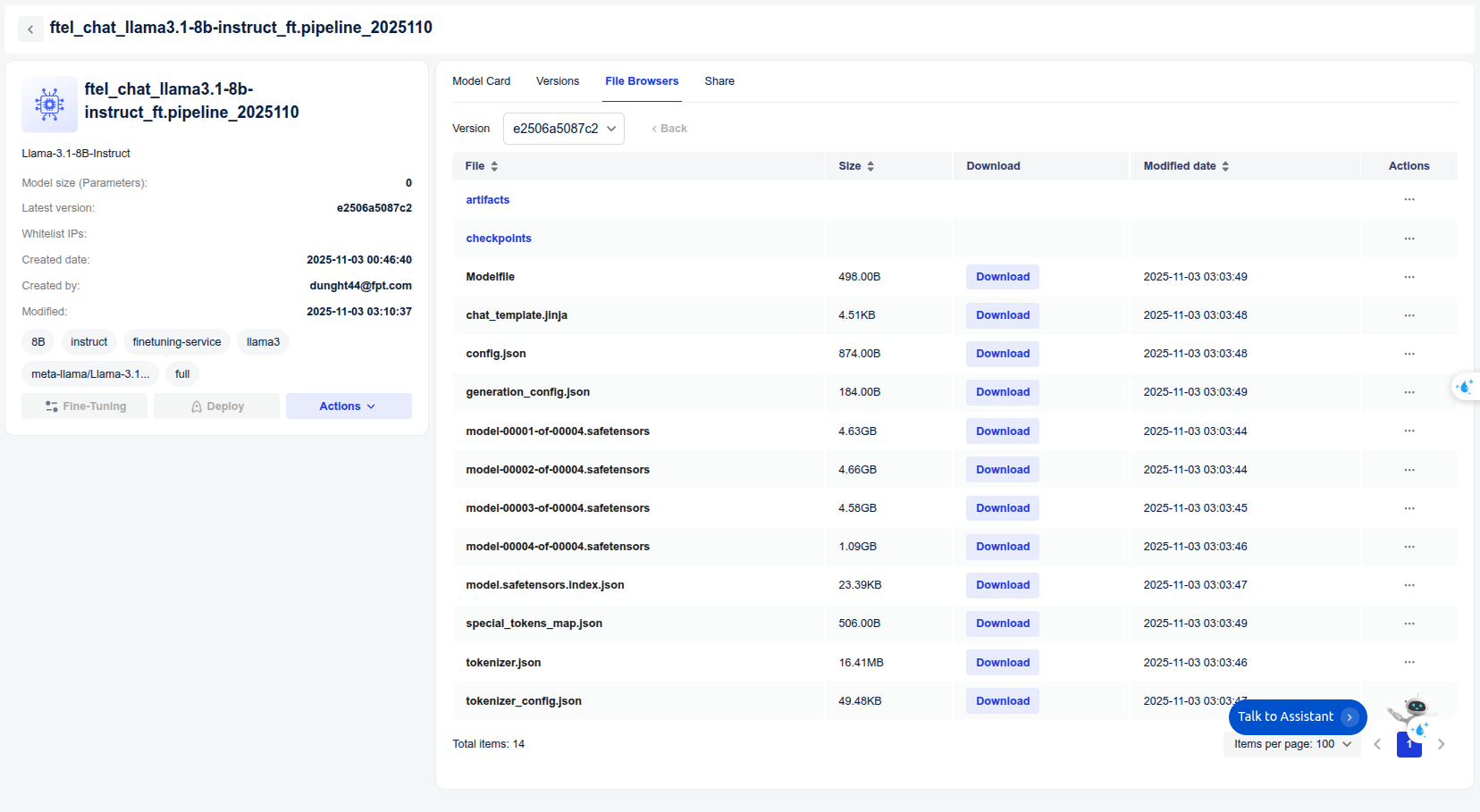
The model, after being trained, is saved in the Private Model section of the Model Hub. Users can download it or use it directly with other services such as Interactive Session or Test Jobs.
4. Model Evaluation
After training, the model's performance was evaluated to ensure it met the required accuracy and efficiency. We use FPT AI Studio's Test Jobs with NLP metrics to evaluate the model on the test set in order to compare the model before and after fine-tuning.
Result:

Note:
📈 All metrics saw a significant boost, demonstrating that the model has strongly internalized task-specific log analysis patterns.
🎯 Fuzzy Match surged from 0.27 → 0.49, highlighting a much tighter alignment with target phrasing.
✨ BLEU jumped from 0.02 → 0.28, signaling notable gains in lexical precision and phrase-level accuracy.
📘 ROUGE metrics improved markedly, indicating a deeper grasp of content structure and more coherent generated summaries.
5. Model Deployment
The fine-tuned model was deployed on FPT AI Studio's Interactive Session. This made the model accessible via an API endpoint, allowing our Streamlit application to send log data and receive analysis results in real-time. In addition, we can chat directly on the Interactive Session interface.
6. Demo Application
The final piece of the project is the Streamlit dashboard, which provides a user-friendly interface for visualizing the real-time log analysis.
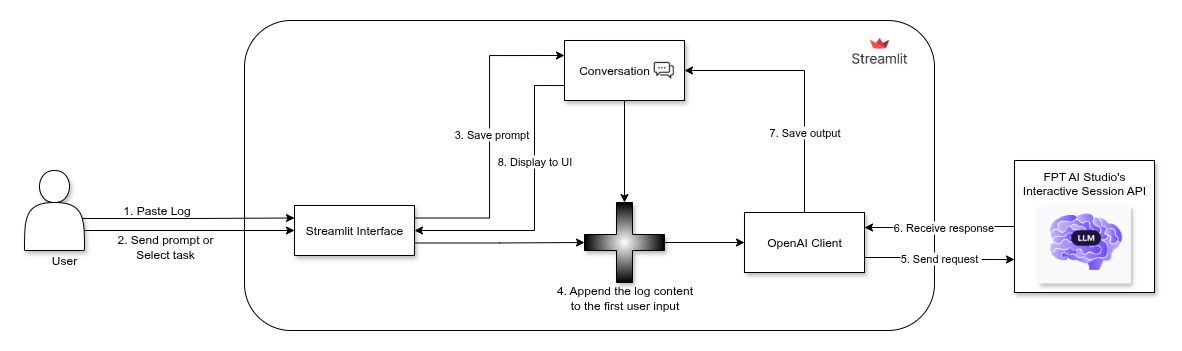
How it works
Interactive Chat Interface
Users can interact directly with the AI model through a chat-style interface. The app supports both freeform queries and predefined analysis tasks such as:
Summarize Log: Generate concise summaries of lengthy log files.
Find Root Cause: Identify potential root causes of detected issues.
Find Patterns: Detect recurring behaviors or anomalies within the logs.
AI-Powered Analysis
When the user triggers a task or sends a question, the app composes a structured request containing both the user’s prompt and the provided log content. This is then sent to the fine-tuned Llama-3.1-8B-Instruct model deployed via FPT AI Studio API, which processes the input and streams back results in real time.
How to run the demo
Streamlit demo results integrating the fine-tuned model:

Step-by-step usage within the app:
Paste your log data into the “Paste the log content here” box in the sidebar. (You should paste 50–150 lines of log.)
Choose the desired analysis task:
✂️ Summarize Log: generate a concise summary of the log.
🔍 Find Root Cause: identify the root cause of errors or incidents.
🧩 Find Patterns: detect patterns or recurring behaviors in the log.
The chatbot will automatically send the request to the model and stream the response in real time.
You can continue chatting with the bot by typing new questions in the input box.
Click New Chat in the sidebar to clear all messages and start a new session.
Last updated
Was this helpful?